I am a regular user. I buy clothes online, I order food, I get things for the home. And, like most people, I have my favourite places. I go back to the same shops because I know them, because I trust them, and — often — because I have a discount or a loyalty price there.
Now watch what happens when I bring an AI assistant into this.
I open ChatGPT and ask it to find the best price for my favourite model of jeans. It runs a generic web search. It uses its own rules about where to look. Even if it happens to land on my favourite store, the price it shows me is the public price — not my price. My discount, my loyalty status, my active promo — none of that is there. The assistant has no idea I am me.
There are two problems tangled together here:
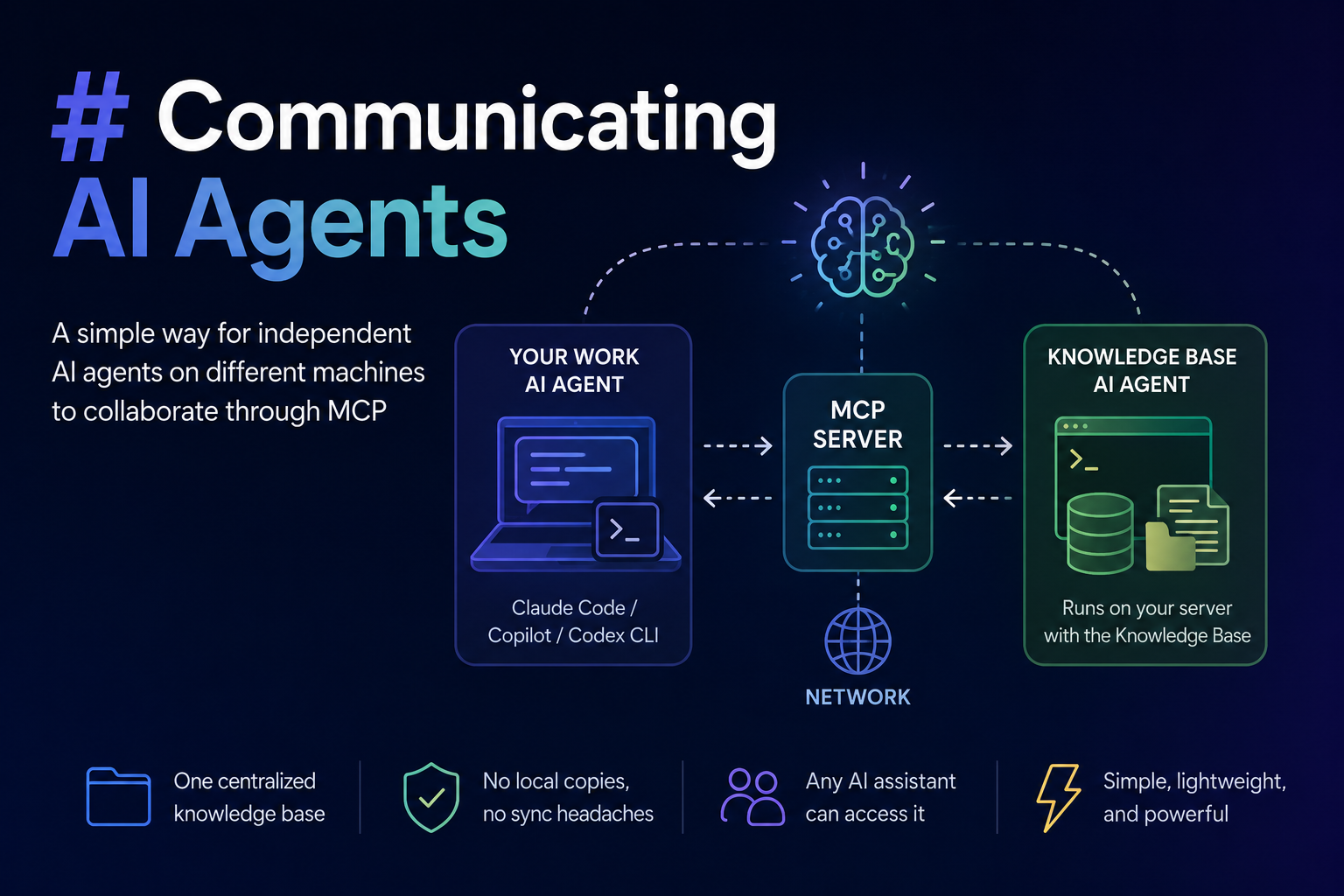
- My favourite store has no MCP interface. The agent can only use the open web, and sometimes a public API. There is no clean way for it to say "this user is a logged-in customer, show them their real prices."
- I can't easily teach the agent my preferences. I would love to just type in the chat: "When I ask you to find clothes, search on https://next.co.uk/ and https://www.riverisland.com/ first." And I'd expect it to remember that and do it next time. Today that is still awkward. For a regular, non-technical user it basically doesn't happen.