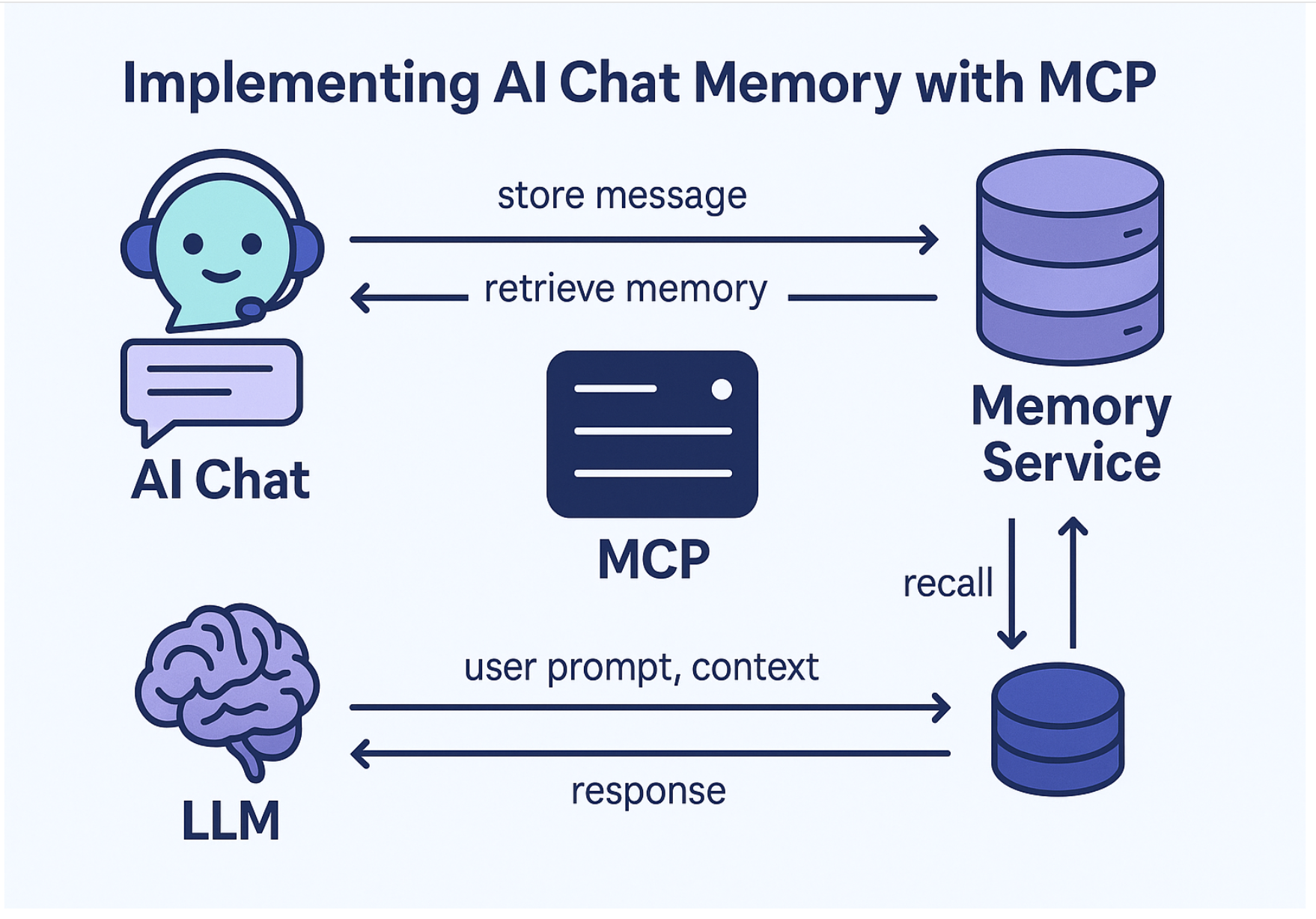
Recently, I introduced the idea of using MCP (Model Context Protocol) to implement memory for AI chats and assistants. The core concept is to separate the assistant's memory from its core logic, turning it into a dedicated MCP server.
If you're unfamiliar with this approach, I suggest reading my earlier article: Benefits of Using MCP to Implement AI Chat Memory.
What Do I Mean by “AI Chat”?
In this context, an "AI Chat" refers to an AI assistant that uses a chat interface, with an LLM (Large Language Model) as its core, and supports calling external tools via MCP. ChatGPT is a good example.
Throughout this article, I’ll use the terms AI Chat and AI Assistant interchangeably.
Key Principles of This Approach
- An AI assistant should not manage its own memory.
- It can delegate memory to an external service.
- MCP can serve as a bridge between the assistant and memory service.
- This enables reuse: multiple assistants can share one memory service, and one assistant can swap between different memory backends.
I’ve implemented this concept in CleverChatty, a Go-based AI assistant framework I recently released. You can read more about the package in this blog post.
Why Do AI Assistants Need Memory?
AI chats need to maintain context — not just for one conversation, but across multiple sessions. They should retain high-level information like:
- The user’s profile (e.g., name, age, interests)
- Key topics the user cares about (projects, goals, tasks)
- A summary of the current conversation
- A broader summary of previous conversations
- The user's current prompt
All of this needs to be packaged with every request sent to the LLM. Most basic assistants just send as much of the prior conversation as fits in the LLM’s context window — but that’s inefficient and not scalable.
How I Built the Memory Layer
CleverChatty now supports an external memory service. This service does only two things:
- Stores new chat messages as they appear.
- Recalls a summary of past conversations before each LLM prompt.
The memory service exposes just two endpoints:
POST /remember: stores a message (includes the role: "user" or "assistant")GET /recall: returns the memory summary
Note: For now, my prototype assumes a single user. In a production system, the memory service would accept a
user_idto handle multiple users and assistants.
Internally, the memory service:
- Stores full message history
- Generates concise summaries using a background worker and a secondary LLM
- Stores both raw and processed data
This allows the assistant to retrieve a context summary tailored to the user's current conversation.
Why Use MCP?
MCP isn’t strictly necessary — any protocol would work — but it's becoming a de facto standard for connecting AI assistants with external tools and services.
By using MCP:
- You get a standardized interface
- You can easily swap out the memory backend
- Assistants can stay decoupled from specific services
Defining a “Memory Interface” in MCP
Here’s a simple interface for a memory service using MCP’s tool schema:
{
"tools": [
{
"name": "remember",
"description": "Store a chat message for later context recall",
"inputSchema": {
"properties": {
"role": { "type": "string" },
"message": { "type": "string" }
},
"required": ["role", "message"]
}
},
{
"name": "recall",
"description": "Return a context summary from previous conversations",
"inputSchema": {
"properties": {},
"required": []
}
}
]
}
MCP currently doesn’t have formal support for service interfaces. I’ve proposed adding this capability — see my feature request.
Integration in CleverChatty
Here’s how a memory service is defined in a CleverChatty config file:
{
"model": "ollama:mistral-nemo",
"mcpServers": {
"Memory_Server": {
"url": "http://memory-server/sse",
"headers": ["Authorization: Bearer ********"],
"interface": "memory"
}
}
}
If a server declares the interface as memory, CleverChatty will:
- Load and isolate the memory tools (
remember,recall) - Exclude them from the LLM’s tool list (to avoid accidental calls)
- Use them automatically to manage memory before and after each prompt
Additional tools (like search) can still be exposed to the LLM.
Workflow:
- On every user message → call
rememberwith role"user" - On assistant response → call
rememberwith role"assistant" - Before calling LLM → call
recallto inject memory into the prompt
The Memory Service Implementation
I’ve built a reference implementation using Python and the MCP SDK.
@mcp.tool()
def remember(role: str, contents) -> str:
Memory(config).remember(role, contents)
return "ok"
@mcp.tool()
def recall() -> str:
return Memory(config).recall() or "none"
@mcp.tool()
def search_in_memory(data: str) -> str:
return Memory(config).search(data)
The Memory class handles all internal logic — storing messages, generating summaries, and managing data. It stores everything in SQLite (suitable for testing, but not production).
A background "worker" script periodically:
- Analyzes new messages
- Summarizes them using another LLM
- Updates the stored context
The CLI included in the project supports:
- Manual memory review
- Summary patching
- Tool simulation
This is where the magic happens — the summary builder ensures only the most relevant data is passed to the LLM.
What Should Be in the Summary?
This is arguably one of the most challenging aspects of building a memory service. Leading AI assistants like ChatGPT and Claude have their own internal methods for summarizing conversations—but they don’t share how it works. It’s a black box. One of the keys to building an effective memory system is finding the right balance between the amount of information and the size of the summary.
The summary needs to be compact enough to fit into the LLM's context window, but rich enough to retain all relevant and useful information.
Here are some important questions to consider when designing your own memory service:
- Should we extract context from the assistant’s messages as well, or just the user’s?
- How frequently should the summary be updated? After every message, or in batches?
- What should be the structure of the data returned by the memory recall?
- How large should the summary be to stay within limits but still be useful?
And, of course, many more decisions will come up depending on your goals and use cases.
Running Locally
1. Set up LLM access
You’ll need a local LLM like ollama or access to OpenAI, Anthropic, or Gemini APIs. See CleverChatty config docs for setup.
2. Clone and run the memory service
git clone https://github.com/Gelembjuk/cleverchatty-memory
cd cleverchatty-memory
python3 -m venv venv && source venv/bin/activate
pip install -r requirements.txt
python main.py
Details are in the README.
3. Create your config file
{
"model": "ollama:mistral-nemo",
"mcpServers": {
"Memory_Server": {
"url": "http://localhost:3001/sse",
"headers": ["Authorization: Bearer ********"],
"interface": "memory"
}
}
}
4. Run CleverChatty CLI
Install or run directly:
go run github.com/gelembjuk/cleverchatty-cli@latest --config config.json
Or clone, build, and run manually.
Build Your Own Memory Service
You can create your own memory service in any language that supports MCP:
- Implement the
memoryinterface - Store and process messages however you like
- Integrate with CleverChatty by updating the config
Use CleverChatty-Memory as a starting point.
Final Thoughts
This is just a proof of concept — but the architecture is solid. Decoupling memory from the assistant using MCP opens the door for experimentation, scalability, and innovation.
Want to try building your own memory backend? Just follow the memory interface spec, plug it into CleverChatty, and see how your AI assistant evolves.