With the recent addition of A2A (Agent-to-Agent) protocol support in CleverChatty, it’s now possible to build powerful, intelligent applications—without writing any custom logic. In this blog post, we’ll walk through how to build an Agentic RAG (Retrieval-Augmented Generation) system using CleverChatty.
🤖 What is Agentic RAG?
The term agentic refers to an agent's ability to reason, make decisions, use tools, and interact with other agents or humans intelligently.
In the context of RAG, an Agentic RAG system doesn’t just retrieve documents based on a user’s prompt. Instead, it:
- Preprocesses the user’s query,
- Executes a more contextually refined search,
- Postprocesses the results, summarizing and formatting them,
- And only then returns the final answer to the user.
This kind of intelligent behavior is made possible by using a Large Language Model (LLM) as the core reasoning component.
The goal of a RAG system is to enrich the user’s query with external context, especially when the required information is not available within the LLM itself. This typically involves accessing an organization’s knowledge base—structured or unstructured—and providing relevant data to the LLM to enhance its responses.
🧠 Basic RAG vs Agentic RAG
In a previous post, we demonstrated how to build a basic RAG setup using CleverChatty and the Model Context Protocol (MCP). That setup connects a user-facing chatbot to a knowledge base via an MCP server.
This works well if your company or app already has an indexed knowledge base (e.g., via ElasticSearch or Pinecone). The MCP server acts as a bridge, letting the agent retrieve relevant information and answer queries:
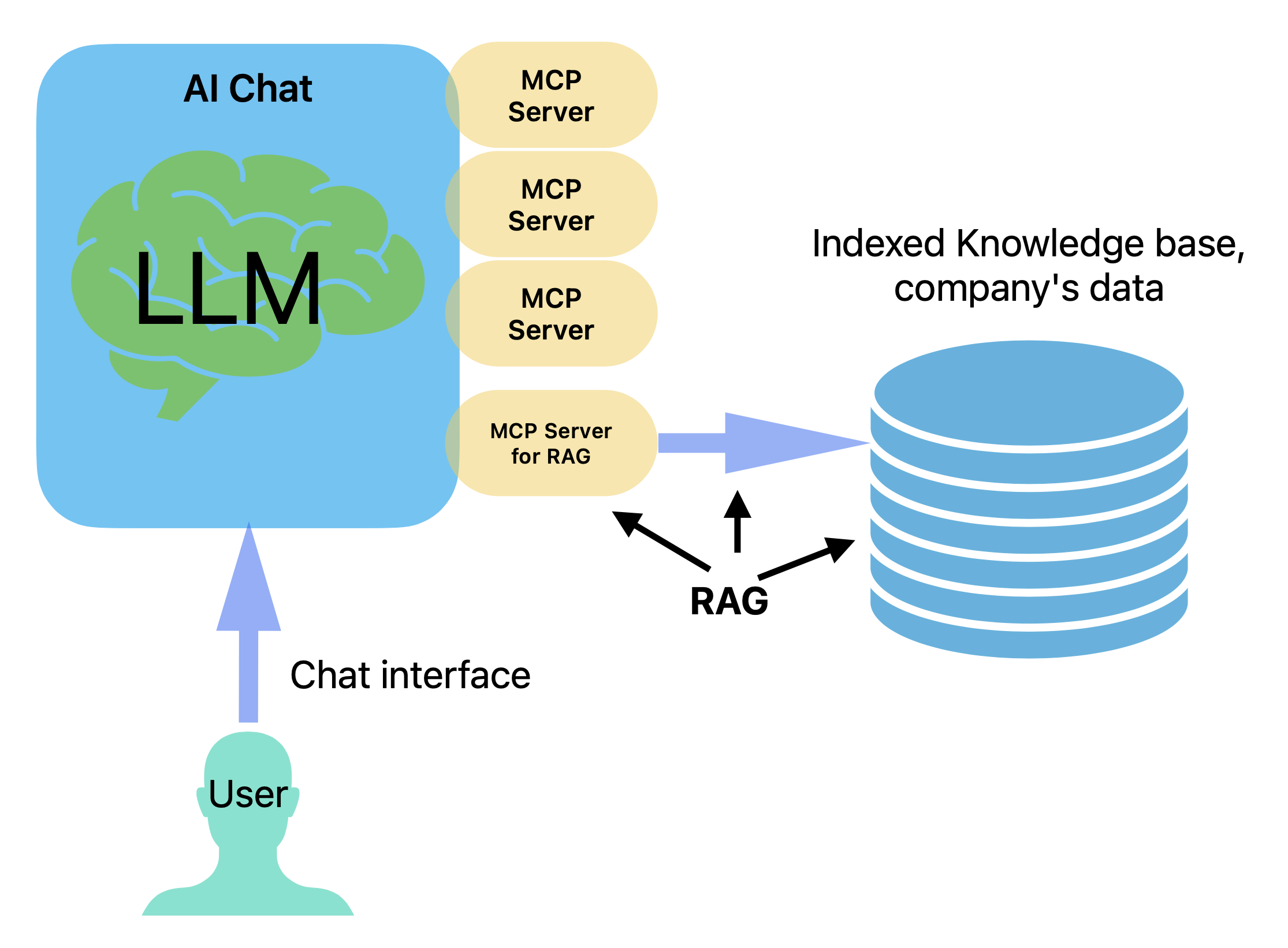
However, this basic setup relies heavily on the user-facing chatbot to formulate accurate search queries and interpret results.
With Agentic RAG, we introduce a specialized agent that handles these tasks more intelligently. It uses an LLM to enhance both the search input and the final response:
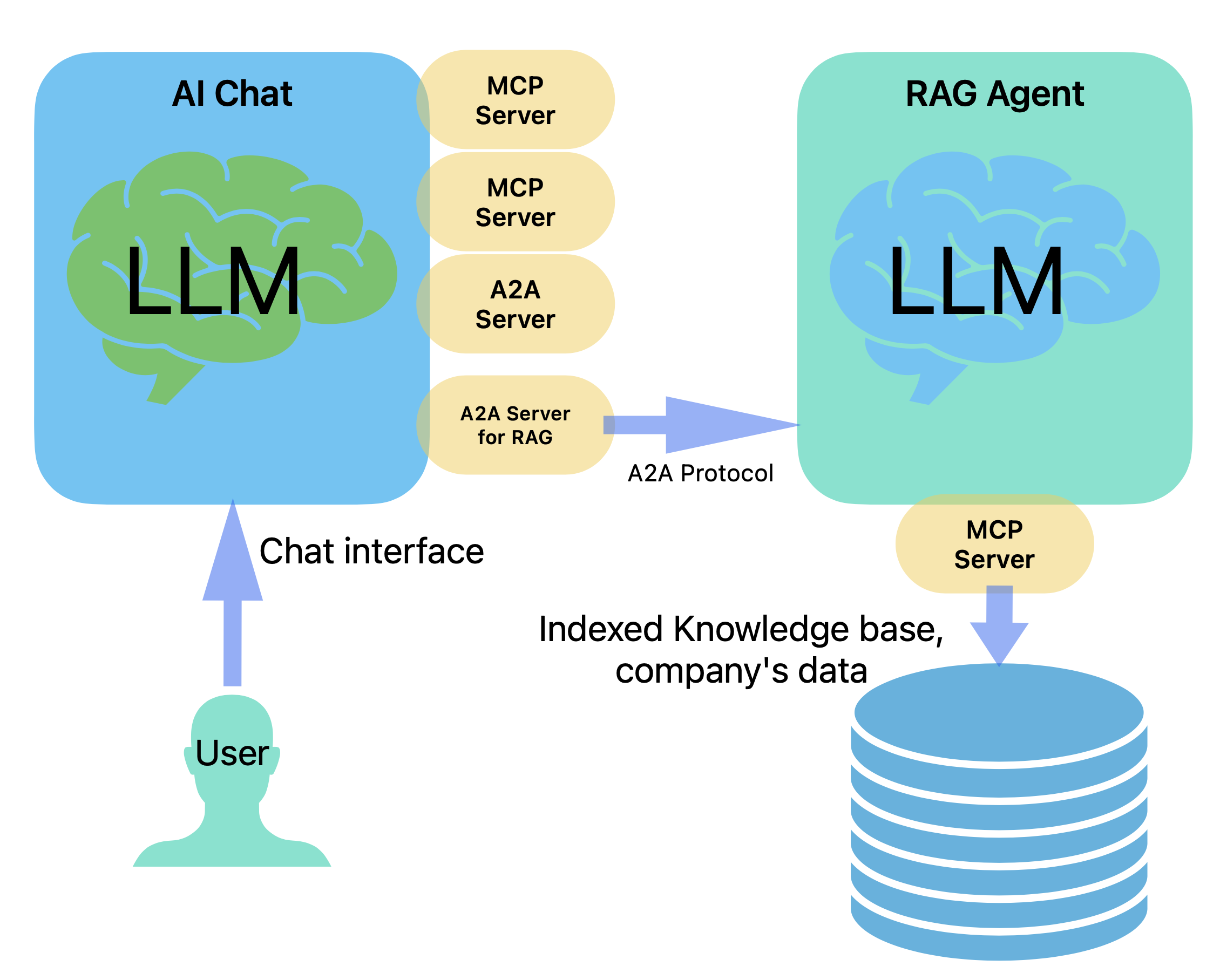
This intelligent agent receives the user’s prompt from the main chatbot via the A2A protocol, processes the query through an LLM, retrieves data from the knowledge base using MCP, and returns a polished response.
🛠️ How to Build an Agentic RAG System with CleverChatty
CleverChatty makes this entire architecture remarkably easy to set up. All you need is:
- A user-facing AI chat server
- An Agentic RAG server
- An MCP server (the knowledge base bridge)
Let’s walk through each component.
📦 Step 1: Install CleverChatty
You’ll need Go installed on your system. Then install CleverChatty server and CLI tools:
go install github.com/gelembjuk/cleverchatty/cleverchatty-server@latest
go install github.com/gelembjuk/cleverchatty/cleverchatty-cli@latest
You now have two commands:
cleverchatty-server: runs an agent servercleverchatty-cli: runs a client to communicate with agents
🧩 Step 2: Create the Agentic RAG Server
Create a working directory (e.g., agentic_rag_server/) and add a cleverchatty_config.json file:
{
"agent_id": "agentic_rag",
"log_file_path": "log_file.txt",
"debug_mode": false,
"model": "ollama:qwen2.5:3b",
"system_instruction": "For any prompt you receive, first preprocess it to generate a more relevant search query. The query must always be forwarded to the search tool. Then, after receiving the search results, postprocess them to summarize and format the response before returning it to the user.",
"tools_servers": {
"knowledge_base_server": {
"command": "uv",
"args": ["run", "knowledge_base_server.py"],
"env": {
"API_KEY": "YOUR_API_KEY"
}
}
},
"a2a_settings": {
"enabled": true,
"agent_id_required": true,
"url": "http://localhost:8080/",
"listen_host": "0.0.0.0:8080",
"title": "Knowledge Base Agentic RAG"
}
}
Key Configuration Notes
system_instruction: Directs the LLM to enhance the search query and summarize results.model: You can replaceollama:qwen2.5:3bwith any other LLM provider (e.g., OpenAI, Anthropic).tools_servers: Defines an external tool (MCP server) that the RAG agent will use to fetch knowledge.a2a_settings: Enables A2A communication so other agents can call this one as a tool.
📚 Step 3: Create the MCP Knowledge Base Server
The MCP server accepts a search query and returns relevant content. Here’s a minimal example using fastmcp:
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("Demo")
@mcp.tool()
def search_in_database(query: str) -> str:
"""Search the knowledge base"""
results = ... # implement your search logic here
return results
This server should be callable by the Agentic RAG agent via the "knowledge_base_server" tool.
🚀 Step 4: Run the Agentic RAG Server
cleverchatty-server start --directory /path/to/agentic_rag_server
The server will listen on http://localhost:8080.
🤝 Step 5: Configure the Main Chat Server
Now create another working directory (e.g., common_ai_chat/) and add this config file:
{
"agent_id": "common_ai_chat",
"log_file_path": "log_file.txt",
"debug_mode": false,
"model": "ollama:llama3.1:latest",
"system_instruction": "You are a helpful AI assistant. You can answer questions and provide information.",
"tools_servers": {
"agentic_rag_server": {
"endpoint": "http://localhost:8080/",
"interface": "rag"
}
},
"a2a_settings": {
"enabled": true,
"agent_id_required": true,
"url": "http://localhost:8081/",
"listen_host": "0.0.0.0:8081",
"title": "Common AI Chat"
}
}
This setup tells the chat server to forward RAG-related queries to the Agentic RAG server via A2A.
▶️ Step 6: Run the Chat Server
cleverchatty-server start --directory /path/to/common_ai_chat
The chat server listens on http://localhost:8081.
💬 Step 7: Test the Agentic RAG System
Now open a new terminal and start the client:
cleverchatty-cli --server http://localhost:8081/ --agent client_id
Try asking a question! Behind the scenes:
- Your prompt goes to the main chat server.
- It forwards the query to the Agentic RAG server.
- The RAG agent uses its LLM to improve the query.
- It fetches knowledge via the MCP server.
- It summarizes the results and returns them.
- The main chat server includes that context when generating a final response.
🌟 Benefits of This Architecture
-
Cost Optimization By assigning different LLMs to different agents, you can significantly reduce token usage costs. For example, the main AI chat server may use a high-end model like OpenAI’s ChatGPT-4.1 to deliver a premium user experience. Meanwhile, the Agentic RAG server can operate on a more cost-effective model such as ChatGPT-3.5 or a local LLM to handle query preprocessing and summarization—tasks that often consume more tokens but require less nuance. This way, expensive models are only used for final user-facing responses.
-
Improved Data Privacy and Access Control Many businesses are cautious about sending sensitive data to external LLM providers. This architecture allows you to isolate internal data access to local agents. For instance, the Agentic RAG server can run a local model like Ollama, ensuring that raw knowledge base content stays within your infrastructure. Only the processed summary is passed to the external-facing AI chat server, keeping sensitive information secure.
-
Modular and Extensible Design Each component in this architecture is independently configurable and replaceable. Want to switch to a different LLM provider or connect a new MCP server? You can do that by updating a single config file—no need to modify the main AI chat server or other agents. This modularity supports rapid development, easy scaling, and seamless upgrades over time.
✅ Summary
With CleverChatty, you can now:
- Combine RAG with LLM-powered agents
- Enable smart query refinement and summarization
- Orchestrate all of this via A2A + MCP—no manual code required
This modular architecture makes it easy to extend your assistant’s capabilities by simply connecting new agents and tools.
🔗 Next Steps
Want help building your own Agentic RAG pipeline? Drop a comment or open an issue on GitHub!

